ケース別データの可視化パターンとpythonによる実装
データが与えられた時、まずは可視化してデータの特徴を把握することが大切です。しかし、何を軸にしてどのように可視化するのかということに関しては、あまりルール化されていないのが現状だと思います。
データから何を知りたいのか?ということから、パターン別にどのように可視化したらいいのかということをチートシート形式で示し、さらにpythonでの可視化方法を順に紹介していきたいと思います。

上のチートシートを参考に、
- Distribution|分布
- Composition|構成
- Relationship|関係
- Comparison|比較
の4つの項目に分けて、どのようなデータパターンではどのように可視化するとわかりやすいか、pythonではどのように実装するのかを記していきます。
準備
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
plt.style.use('ggplot')
plt.rcParams.update({'font.size':15})
%matplotlib inline
可視化には主に、matplotlib.pyplot、seabornを使います。seabornに馴染みのない方は、この記事を見るといいと思います。
Distribution|分布
1変数の分布
データポイントが数個の場合|ヒストグラム
x = np.random.normal(size = 1000) plt.hist(x) plt.show()
データポイントが多い場合|線グラフヒストグラム
x = np.random.normal(size = 1000) # ここのみ、seabornを用いて可視化 sns.distplot(x)
2変数の分布|散布図
x = range(1, 101) y = np.random.randn(100)*15 + range(1, 101) plt.scatter(x, y) plt.show()
Composition|構成

時間ごとの構成
時間軸が複数個の場合
割合のみを見たい場合|累積棒グラフ
x = [1, 2, 3, 4, 5] y1 = [80, 60, 40, 20, 5] y2 = [20, 40, 60, 80, 95] plt.bar(x, y1) plt.bar(x, y2, bottom=y1)
割合と値を両方見たい場合|棒グラフ
x = [1, 2, 3, 4, 5] y1 = [100, 200, 300, 400, 500] y2 = [1000, 800, 600, 400, 200] plt.bar(x, y1) plt.bar(x, y2, bottom=y1)
時間軸が多い場合
割合のみを見たい場合|累積エリアチャート
x = range(1, 7) y1 = [0, 20, 40, 30, 40, 100] y2 = [40, 50, 20, 40, 55, 0] y3 = [60, 30, 40, 30, 5, 0] plt.stackplot(x, y1, y2, y3) plt.show()

割合と値自体を両方見たい場合|エリアチャート
x=range(1, 7) y1=[1, 4, 6, 8, 9, 3] y2=[2, 2, 7, 10, 12, 10] y3=[2, 8, 5, 10, 6, 8] plt.stackplot(x,y1, y2, y3) plt.show()
静的カテゴリごとの構成
全体に占める割合を見たい場合|円グラフ
x = [100, 200, 300, 400, 500]
label = ["A", "B", "C", "D", "E"]
plt.pie(x, labels=label)
plt.axis('equal') # 出力が楕円形になるのを防ぐため
plt.show()
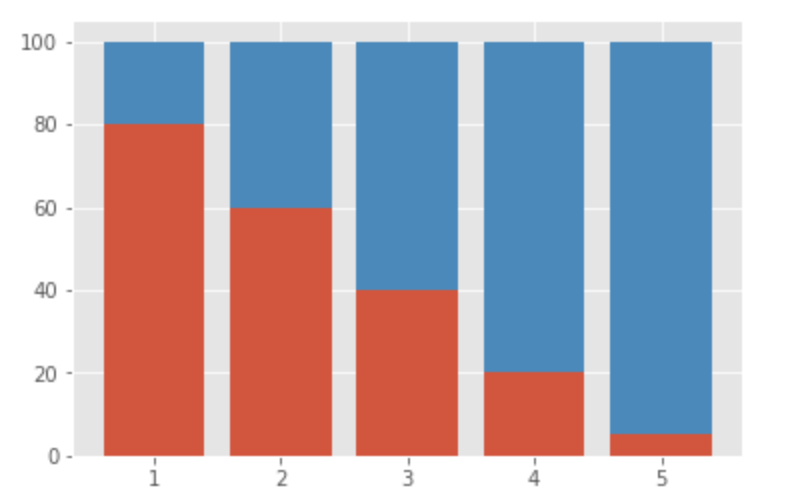
構成の構成を見たい場合|累積棒グラフ
x = [1, 2, 3, 4, 5] y1 = [80, 60, 40, 20, 5] y2 = [20, 40, 60, 80, 95] plt.bar(x, y1) plt.bar(x, y2, bottom=y1)
全体に対する累積値と値自体を見たい場合|ツリーマップ
import squarify
x = [13,22,35,5]
label = ["A", "B", "C", "D"]
squarify.plot(x, label=label)
plt.axis('off')
plt.show()

Relationship|関係
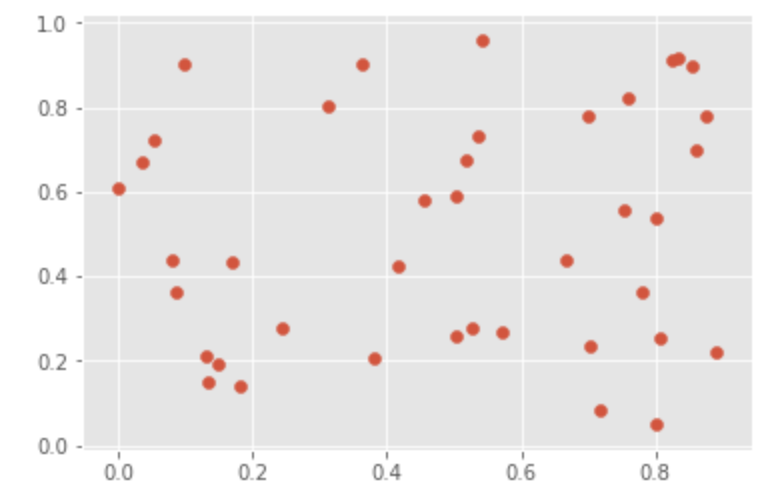
変数が2つの場合|散布図
x = range(1, 101) y = np.random.randn(100)*15 + range(1, 101) plt.scatter(x, y) plt.show()
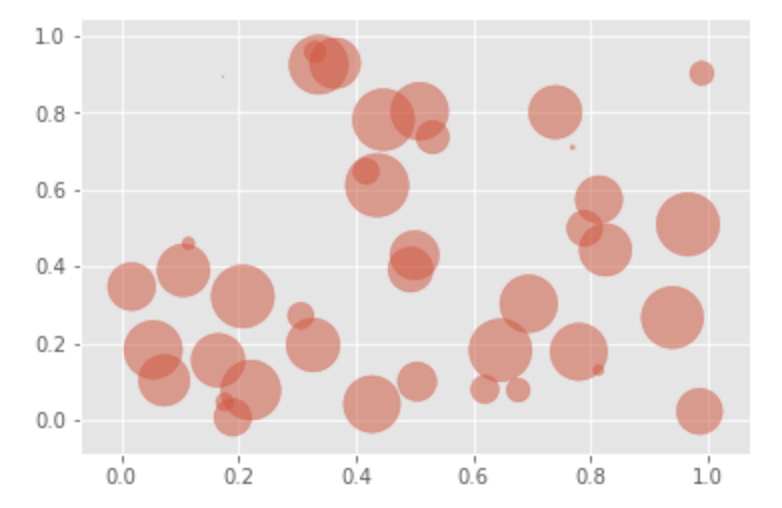
変数が3つの場合|散布図
x = np.random.rand(40) y = np.random.rand(40) z = np.random.rand(40) plt.scatter(x, y, s=z*1000, alpha=0.5) plt.show()
Comparison|比較
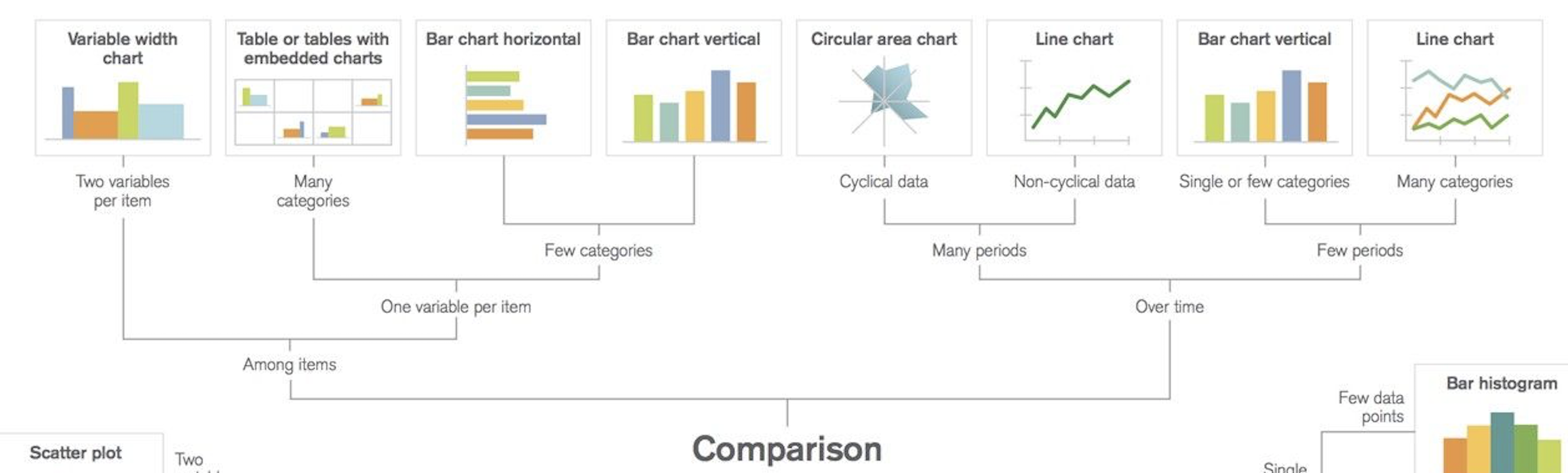
アイテム間の比較
アイテムごとの1変数を比較したい場合
カテゴリが少ない場合|縦棒グラフ・横棒グラフ
x = [1, 2, 3, 4, 5] y = [80, 60, 40, 20, 5] plt.bar(x, y) plt.show()
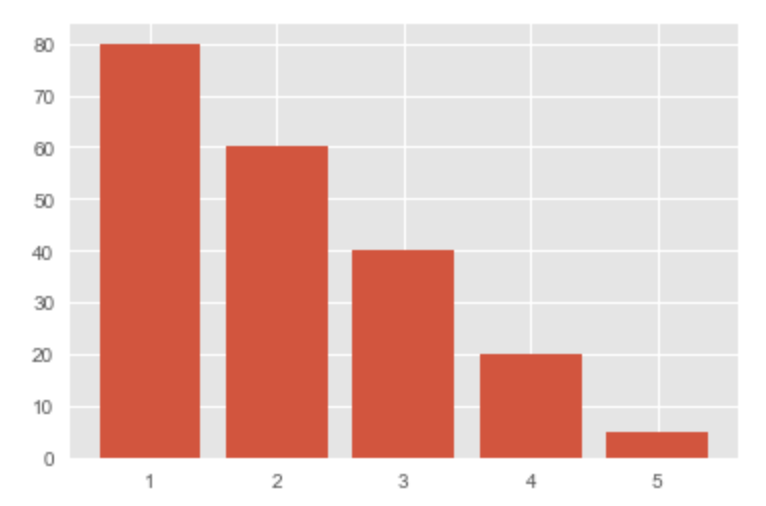
x = [1, 2, 3, 4, 5] y = [80, 60, 40, 20, 5] plt.barh(x, y) plt.show()

カテゴリが多い場合
iris = sns.load_dataset("iris")
sns.pairplot(iris, hue="species", size=2.5)

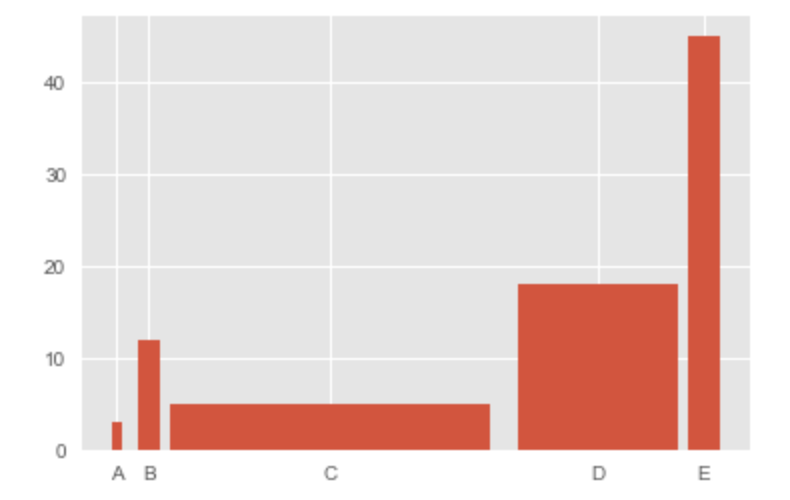
アイテムごとの2変数を比較したい場合|棒グラフ
y = [3, 12, 5, 18, 45]
x = ('A', 'B', 'C', 'D', 'E')
x_width = [0.1, 0.2, 3, 1.5, 0.3]
y_pos = [0, 0.3, 2, 4.5, 5.5]
plt.bar(y_pos, y, width=x_width)
plt.xticks(y_pos, x)
plt.show()
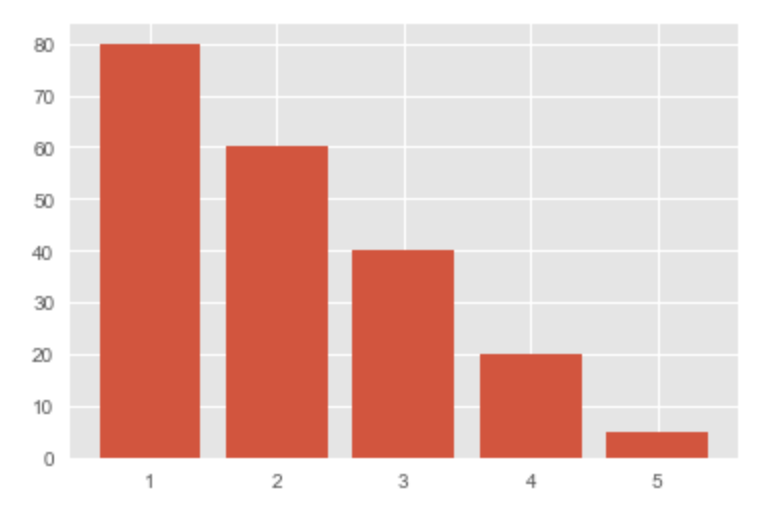
時間軸による比較
時間軸が少ない場合
カテゴリが1つもしくは数個の場合|棒グラフ
x = [1, 2, 3, 4, 5] y = [80, 60, 40, 20, 5] plt.bar(x, y) plt.show()
カテゴリが多い場合|線グラフ
x = range(1,11) y1 = np.random.randn(10) y2 = np.random.randn(10)+range(1,11) y3 = np.random.randn(10)+range(11,21) plt.plot(x, y1) plt.plot(x, y2) plt.plot(x, y3) plt.show()
時間軸が多い場合
非循環データの場合|線グラフ
y = np.cumsum(np.random.randn(1000,1)) plt.plot(y)
参考サイト
5分でスッキリ理解するベイズ推定
ベイズ推定を学ぶモチベーション
ベイズ推定は、Wikipediaに以下のように説明されています。
ベイズ推定(ベイズすいてい、英: Bayesian inference)とは、ベイズ確率の考え方に基づき、観測事象(観測された事実)から、推定したい事柄(それの起因である原因事象)を、確率的な意味で推論することを指す。
マイクロソフトのビルゲイツは自社が競争上優位にあるのはベイズ統計によると宣言したり、グーグルでは検索エンジンの自動翻訳システムでベイズ統計の技術を活かしていることが知られています。
ベイズ推定の強みは、 1. 「データが少なくても推測でき、データが多くなるほど正確になる」という性質 2. 「入ってくる情報に瞬時に反応して、自動的に推測をアップデートする」という学習機能 にあります。
これらの強みを頭に置きながら、本題の「ベイズ推定とは」を見ていきます。
ベイズ推定を図で理解する
洋服屋さんの店員を考えます。この店員さんは常に「このお客さんは買うつもりなのか、それとも買うつもりはさらさらなく商品を見ているだけなのか」と考えています。前者のお客さんには積極的に話しかけに行って購買につなげたい、後者はそもそも買わないし声をかけても煩わしく思われるだけなので話しかけないという行動につなげたいからです。したがって、お客さんの行動から、お客さんのタイプを見極めることが大切になります。
まず、推測のために「買う人(A)」「買わない人(B)」の2タイプに分けて、その割合(確率)を割り振ることから始めます。お客さん全体を見たときに、買う人はだいたい0.2、買わない人は0.8だろうという感じにです。これを事前確率と呼びます。
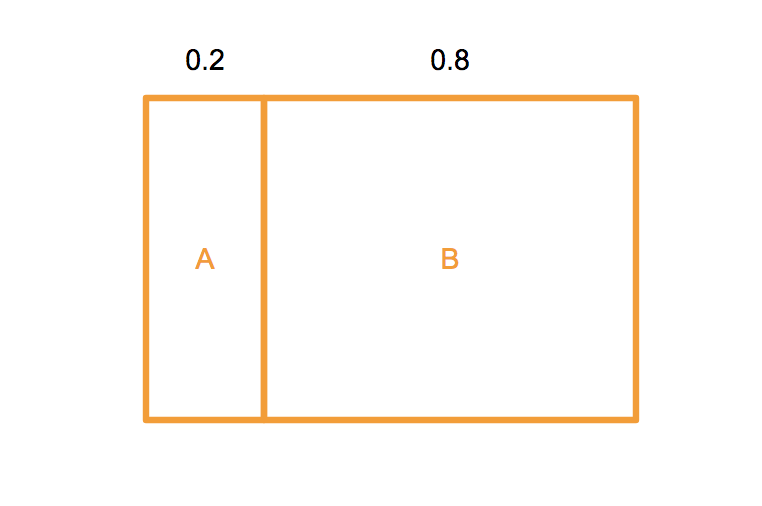
次に、お客さんが店員に「声をかける」という行動に関して確率を割り振ります。買う人なら9割が声をかけるだろう、買わないのに声をかける人は3割だろうという感じです。

次に、店員はお客さんに声をかけられたとしましょう。店員は、お客さんの行動を1つ観察したことになります。これは追加的な情報です。「声かけをしない」という可能性が消えて、確率が変化します。

最後に、そのお客さんが買う人であるという確率を求めます。この、「声かけしてきたお客さんが買う確率」を事後確率と呼びます。
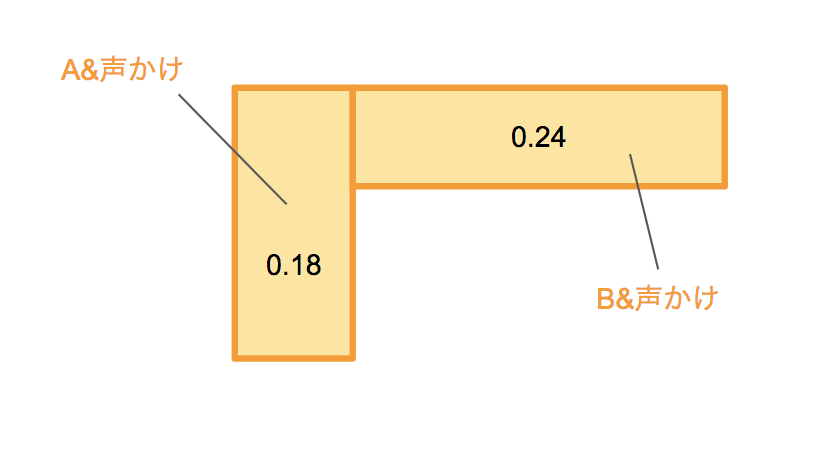
$0.18 : 0.24 = 3 : 4$です。つまりそのお客さんが買う確率は$3/7$となります。
声かけをしてきたという追加情報により、そのお客さんが買う人である確率は、0.2から0.43と約2倍に高まりました。これをベイズ更新と言います。
以上より、ベイズ推定とは「事前確率を行動の観察(情報)によって事後確率へとベイズ更新すること」と定義することができます。
ベイズ推定を式で理解する
$P(X)$を$X$という事象が起こる確率と定義します。 お客さんが買う人である確率は、$P(A) = 0.2$、買わない人である確率は、$P(B) = 0.8$です。
次に、本題である「声かけをしてきたお客さんが買う確率(Aである確率)」を考えます。これを$P(A|声)$と表します。すると、以下のような定式化ができます。
P(A|声) = \frac{P(声|A)P(A)}{P(声)} = \frac{P(声|A)P(A)}{P(声|A)P(A) + P(声|B)P(B)}
これも式だけ見ていても理解できないので、先ほどの図を見て見ましょう。
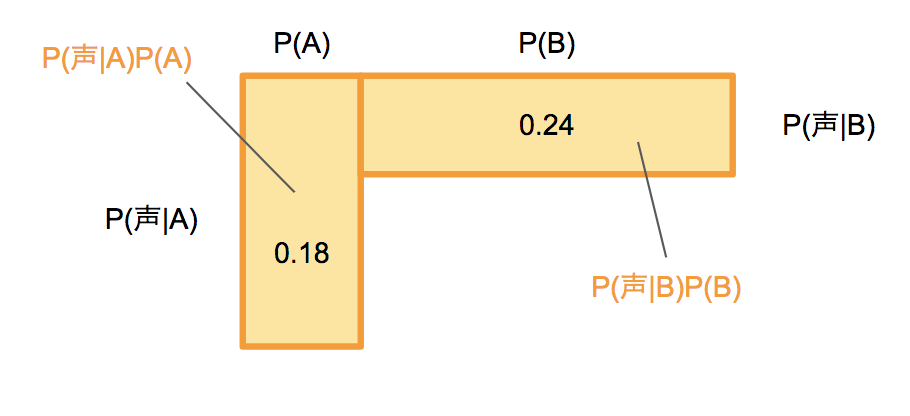
すると、
P(A|声) = \frac{P(声|A)P(A)}{P(声|A)P(A) + P(声|B)P(B)} = \frac{0.18}{0.18 + 0.24} = 0.428...
と、「声かけをしてきたお客さんが買う確率(Aである確率)」すなわち$P(A|声)$は、$0.428...$と求まります。
この式を一般化すると、「Yという事象が起こった時にXという事象が起こる条件付き確率」は、
P(X|Y) = \frac{P(Y|X)P(X)}{P(Y)}
で表され、$P(X)$を事前確率、$P(X|Y)$を事後確率もしくは条件付き確率、$P(Y|X)$を尤度といいます。
ベイズ推定の応用例
ベイズ推定の強みは、 1. 「データが少なくても推測でき、データが多くなるほど正確になる」という性質 2. 「入ってくる情報に瞬時に反応して、自動的に推測をアップデートする」という学習機能 にあります。
と一番最初に述べました。ベイズ推定は、これらの強みを活かせる場面で積極的に使われています。例えば、
- 迷惑メールフィルタ
- 記事のカテゴリ分類
などです。本記事ですっきり理解したベイズ推定の方法は、上の場面ではどのように応用されているのか考えてみるのが良いのではないでしょうか。
MobileNetV2: Inverted Residuals and Linear Bottlenecks_翻訳・要約

MobileNetV1: 概要
MobileNetV1(以下V1)1 では、通常のconvolutionを、depthwise convolutionとpointwise convolutionの2つのサブタスクからなるdepthwise separable convolutionに置き換えることで計算コスト・パラメータ数を大きく削減した。ほぼ同じ精度で、計算コストを1/9ほどに削減ができた。
また、width multiplier / resolution multiplier というハイパーパラメータを導入することで、各層のチャネル数 / 解像度を小さくし、精度は下がってしまうものの、計算コスト・パラメータ数を大きく削減することができた。
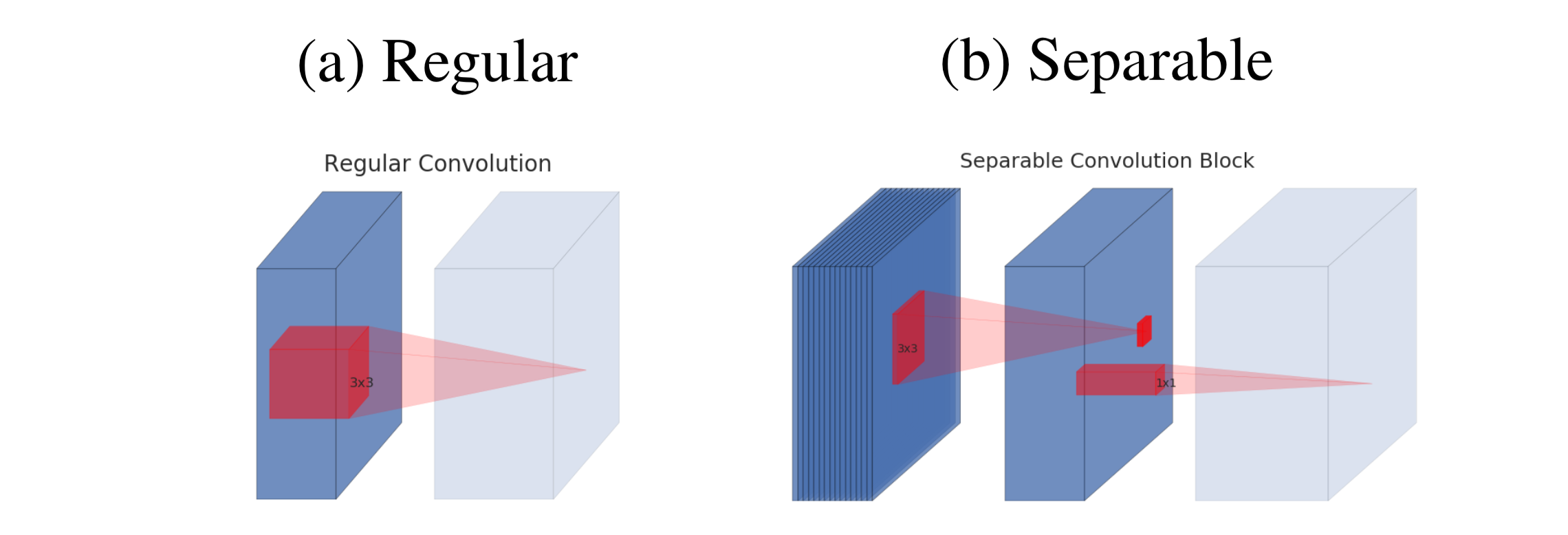
図1: 通常のconvolution(a)とdepthwise separable convolution(b)のイメージ比較 [^1]
MobileNetV2: 構造
MobileNetV2(以下V2)2 はV1同様に、基本的にdepthwise separable convolutionを用いている。V2では、さらに expand/projection layers と inverted residual block がポイントになる。
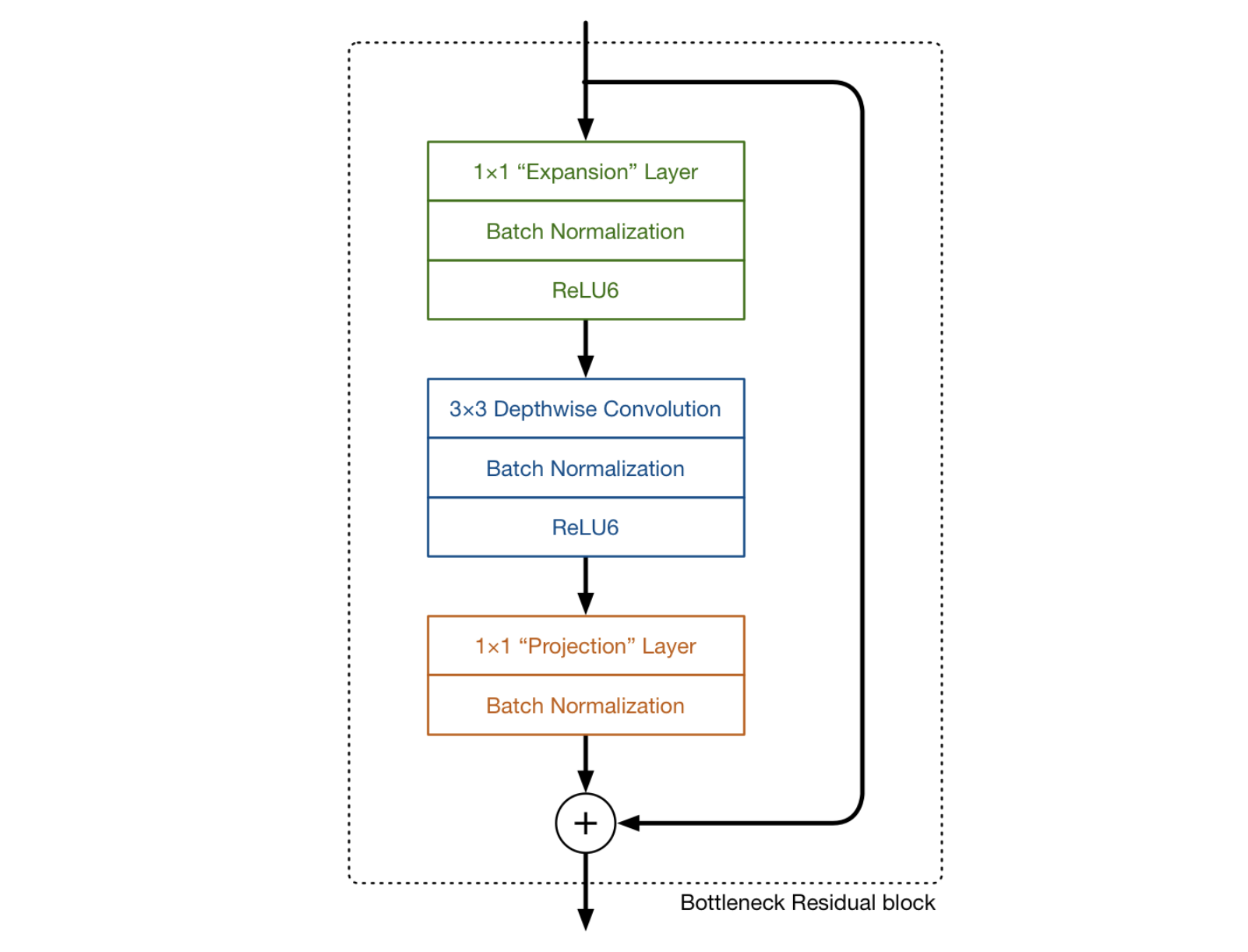 図2: MobileNetV2における畳み込みのイメージ 3
図2: MobileNetV2における畳み込みのイメージ 3
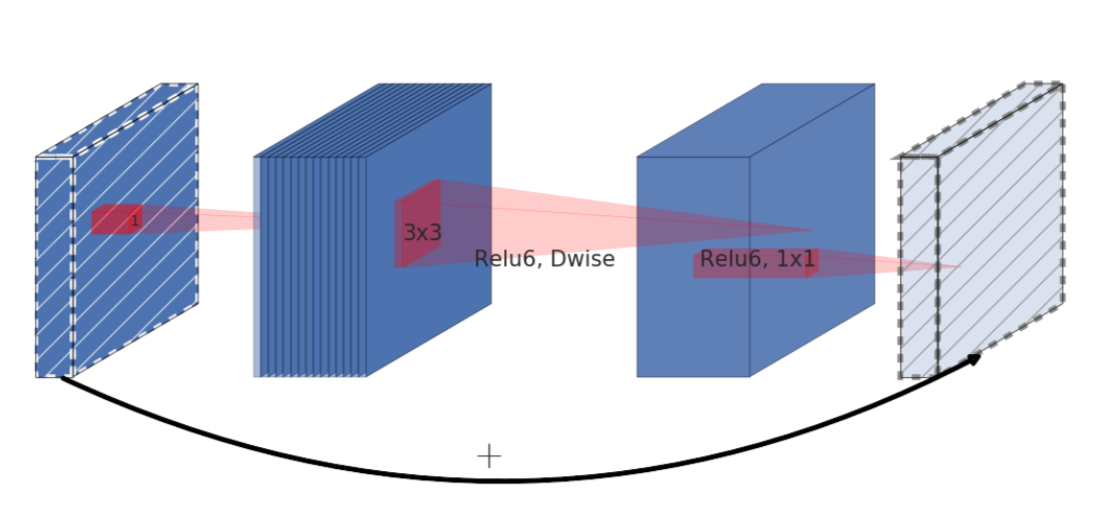 図3: MobileNetV2における畳み込みのイメージその2 [^2]
図3: MobileNetV2における畳み込みのイメージその2 [^2]
expansion/projection layers
図2における2番目と3番目の層はそれぞれ、depthwise separable convolution の depthwise convolution と pointwise convolution である。 pointwise convolution に関しては、V1においてはチャネル数を1倍、もしくは2倍にする役割を持っていたが、V2では、チャネル数を小さくする役目をする。そのため、V2ではprojection layerとも呼ばれている。 projection layer は、高次元(チャネル)を大幅に低次元にするという点で、V2において重要な役割を持つ。
例えば、144チャネルのインプットデータに対して depthwise layer が畳み込みを行う場合、 projection layer はそれを24次元まで削減する。このような層を bottleneck layer とも呼ぶ。これは、出力されるブロックがボトルネックであり、 bottleneck layer はネットワークを流れるデータを大きく削減するから、こう命名されている。
図3における、1番目の層はV2で初めて出てきたものである。これも 1×1 convolution であり、depthwise convolution に入る前にチャネル数を大きくするという役割を持つ。このとき、チャネル数を大きくする割合を expansion factor と呼び、ハイパーパラメータとして扱う。通常6が使われる。
例えば図4では、24チャネルの tensor がブロックに入ってきたとき、 expansion layer が 24 * 6 = 144チャネルにする。次に、depthwise convolution がそのまま144チャネルの tensor として出力し、最後に projection layer が24チャネルにまで小さくする。
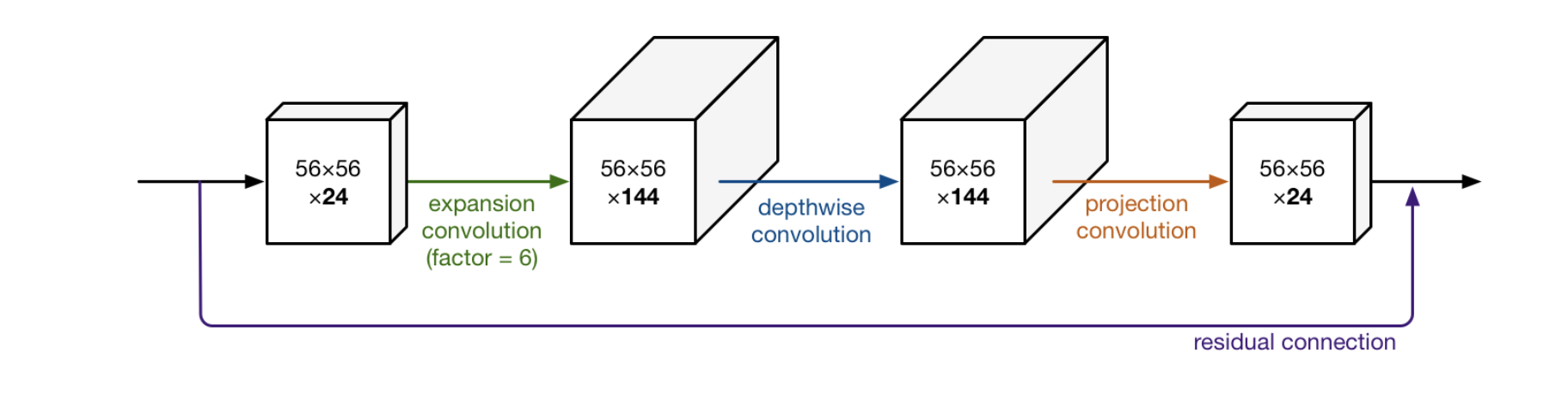 図4: MobileNetV2における畳み込みのイメージ その3 [^3]
図4: MobileNetV2における畳み込みのイメージ その3 [^3]
インプットとアウトプットは低次元の tensor であり、途中経過は高次元の tensor であるというのが特徴である。
inverted residual block
2つめの特徴は、inverted residual blockである。これは、勾配の流れを調節するためにインプットtensorとアウトプットtensorを足し合わせる役割を持つ。
MobileNetV2: ネットワーク構造
表1は、V2のネットワーク構造である。tは expansion factor であり、expansion layerでの拡大率である、cは出力チャネル数、nはそのブロックの繰り返し数、sは stride である。
 表1: MobileNetV2のネットワーク構造 [^2]
表1: MobileNetV2のネットワーク構造 [^2]
V2とV1の比較: なぜV2はV1より優れているのか?
一般的に畳み込みでは、層を重ねるごとにチャネル数は大きくなっていき、空間方向の次元は半分になる。V1では、 7×7×1024 までサイズが大きくなるのに対して、V2では、7×7×324 と小さい。tensor が低次元である方が、計算量は小さくなるので、V2のほうが計算量が小さくなっているとわかる。
一方で、低次元の tensor では、情報量を十分に抽出できないという問題もあるため、より精度を出すためには、高次元な tensor を用いて学習したいと考えられる。V2では expansion layer でデータのチャネル数を大きくし、フィルタを適用し、projection layer でチャネル数に戻すというやり方をとっているからである。
conv1x1の計算量がボトルネックとなっているので、1つの計算量の大きなconv1x1を、計算量の小さなconv1x1を2つ利用することで近似しているということである。具体的には、入出力チャネル数が$N$のconv1x1の計算量は$HWN2$である。これに対し、入力チャネル数が$N$、出力チャネル数が$N/t$のconv1x1と、入力チャネル数が$N/t$、出力チャネル数が$N$のconv1x1の計算量の合計は$2HWN2/t$となる。ここで、$t$はチャネルの拡張率 (expansion factor) である。 $t=6$の場合、conv1x1の計算量が$1/3$になることが分かる。4
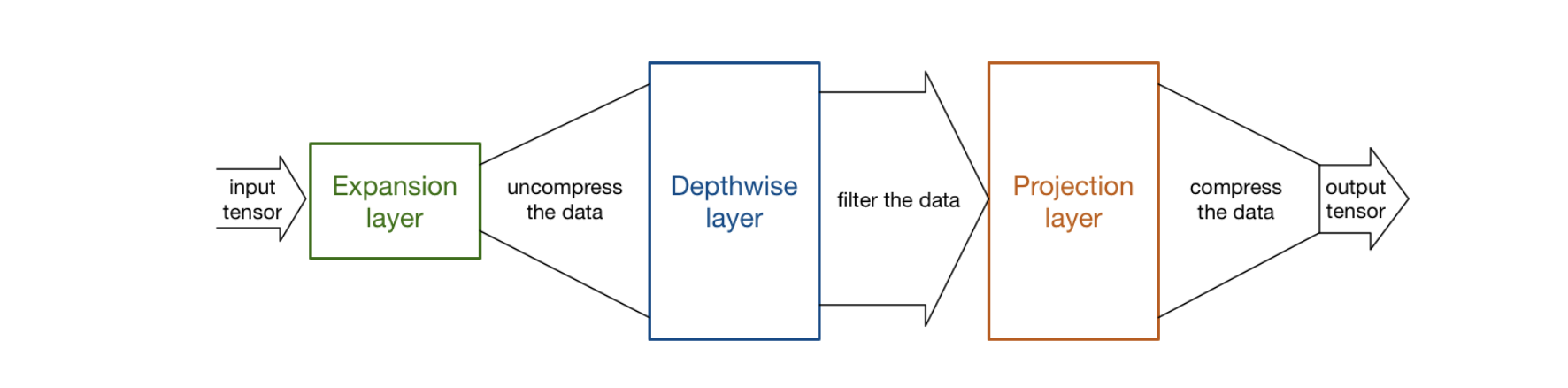 図5: MobileNetV2における畳み込みのイメージ その4 [^3]
図5: MobileNetV2における畳み込みのイメージ その4 [^3]
V2とV1の比較: 実験結果より
Object detection
Object detection における、V2とV1の比較である。V2はV1よりも精度が高く、さらにParams/MAdds/CPUともに小さいという結果が出ている。また、width multiplier を1.4に設定すると、精度は大きく向上するが、Params/MAdds/CPUともにV1よりも大きくなってしまう。
 表2: Object detection におけるV2とV1の比較 [^2]
表2: Object detection におけるV2とV1の比較 [^2]
図6は、V2(resolution multiplier 0.35, 0.5, 0.75, 1.0, 1.4), V1, NasNet, ShuffleNetの精度比較である。
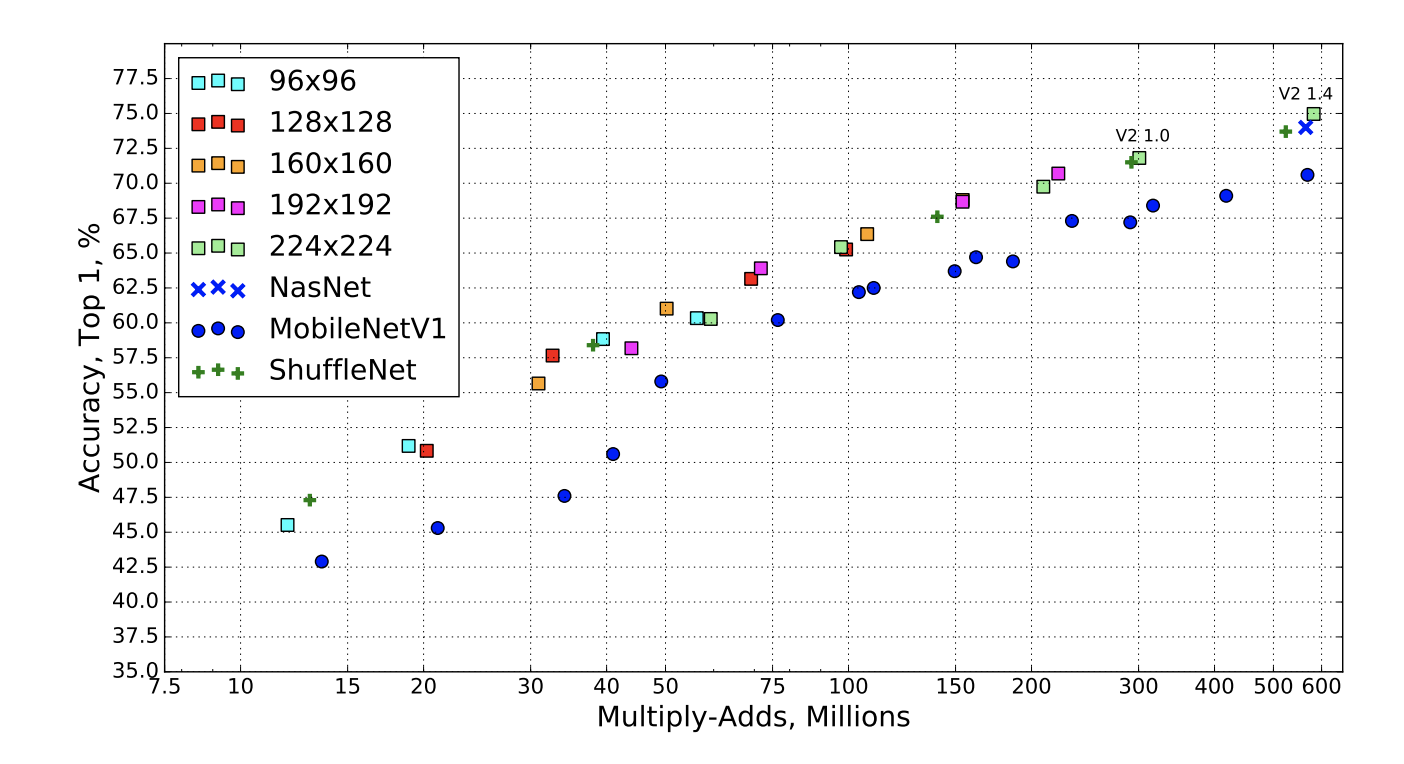 図6: V2, NasNet, V1, ShuffleNetの計算量と精度の比較 [^2]
図6: V2, NasNet, V1, ShuffleNetの計算量と精度の比較 [^2]
図7は、non-linearities と residual connectionsのパフォーマンス比較である。(a)よりbottleneck layerで活性化関数として線形なRelu6を用いるより、非線形性の処理をした方が精度が上がることが示されている。(b)では、expansion layer 間のショートカットより、bottleneck間のショートカットのほうが精度が高いことがわかる。
 図7: non-linearities と residual connectionsのパフォーマンス比較 [^2]
図7: non-linearities と residual connectionsのパフォーマンス比較 [^2]
この論文では、Single Shot Detector (SSD)5をよりmobileフレンドリーにしたモデルを提案している。SSDのprediction layerを全てseparable convolutions (depthwise followed by 1 × 1 projection)で置き換えたモデルをSSDLiteと定義した。表3にあるように、パラメータ・計算コスト共に、SSDと比較して大きく下がっていることがわかる。
また、COCOデータセットにおけるObject detectionにおいては、MobileNetV2 + SSDLite という組み合わせが最も低いパラメータと計算コスト、かつ高い精度を出した。(表4)
 表3: SSDとSSDLiteのパラメータ・計算コストの比較 [^2]
表3: SSDとSSDLiteのパラメータ・計算コストの比較 [^2]
 表4: COCO dataset object detection task におけるMobileNetV2 +
SSDLiteと他の手法の比較 [^2]
表4: COCO dataset object detection task におけるMobileNetV2 +
SSDLiteと他の手法の比較 [^2]
参考文献
-
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” in arXiv:1704.04861, 2017.↩
-
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen, “MobileNetV2: Inverted Residuals and Linear Bottlenecks” in arXiv:1801.04381, 2018↩
-
MATTHIJS HOLLEMANS, “MobileNet version 2” in 2018↩
-
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu and Alexander C. Berg, “SSD: Single Shot MultiBox Detector,” in arXiv: 1512.02325, 2016.↩
MobileNets: CNNのサイズ・計算コストの削減手法_翻訳・要約

TL;DL
MobileNetsはDepthwise Separable Convolutionを用いることで、通常のCNNと比べて軽いネットワークを構築することがでる。また2つのハイパーパラメータである、width multiplierとresolution multiplierを導入することで、latencyとaccuracyを調節することができる。この技術を用いることで、性能や応答時間に制限があるモバイル上のアプリケーションなどにおいても認識や分類モデルへの応用が可能になる。
MobileNet Architecture
Depthwise Separable Convolution
- depthwise separable convolutions
- depthwise convolution
- pointwise convolution (1×1 convolution)
という構造になっている。
たとえば、112 x 112 x 32という入力に対して、通常のCNNでは、3 x 3 x 32 x 64のカーネルを用いて畳み込みを行い、112 x 112 x 64の出力をする。(図1) 一方で、Depthwise Separable Convolutionでは、まず3 x 3 x (1) x 32のフィルタを用いて、depthwise convolutionを行う。この出力は、112 x 112 x 32のままである。次に、1 x 1 x 32 x 64のフィルタを用いて、pointwise convolutionを行う。この出力が56 x 56 x 64になる。(図2)
 図1: 通常の畳み込みイメージ
図1: 通常の畳み込みイメージ
 図2: depthwise separable convolutionsのイメージ
図2: depthwise separable convolutionsのイメージ
また、入力の特徴マップサイズを$D{F} · D{F} · M$、出力の特徴マップサイズを$D{F} · D{F} · N$、カーネルのサイズを$D{K} · D{K} · M · N$とすると、通常の畳み込みの計算コストは、
D_{K} · D_{K} · M · N · D_{F} · D_{F} = D_{K}^2MND_{F}^2
である。一方で、depthwise convolutionでは、チャネル方向への畳み込みを行わないため、$M = 1$であり、計算コストは、
D_{K} · D_{K} · N · D_{F} · D_{F} = D_{K}^2ND_{F}^2
また、pointwise convolutionでは、空間方向の畳み込みを行わないため、$D_{K} = 1$であり、計算コストは、
M · N · D_{F} · D_{F} = MND_{F}^2
よって、Depthwise Separable Convolutionでは、計算コストは、
D_{K}^2ND_{F}^2 + MND_{F}^2 = (D_{K}^2 + M)ND_{F}^2
通常の畳み込みに比べて、Depthwise Separable Convolutionは、
\frac{(D_{K}^2 + M)ND_{F}^2}{D_{K}^2MND_{F}^2} = \frac{1}{M} + \frac{1}{D_{K}^2}
だけ、計算コストが削減できている。上の例では、$M = 32$、$D_{K} = 3$であるから、約9倍ほど計算コストが削減されることがわかる。
このようなやり方を取ることで、通常の畳み込みと比べて計算コストとモデルのサイズをかなりの度合いで小さくすることができる。
NNの構造とtraining
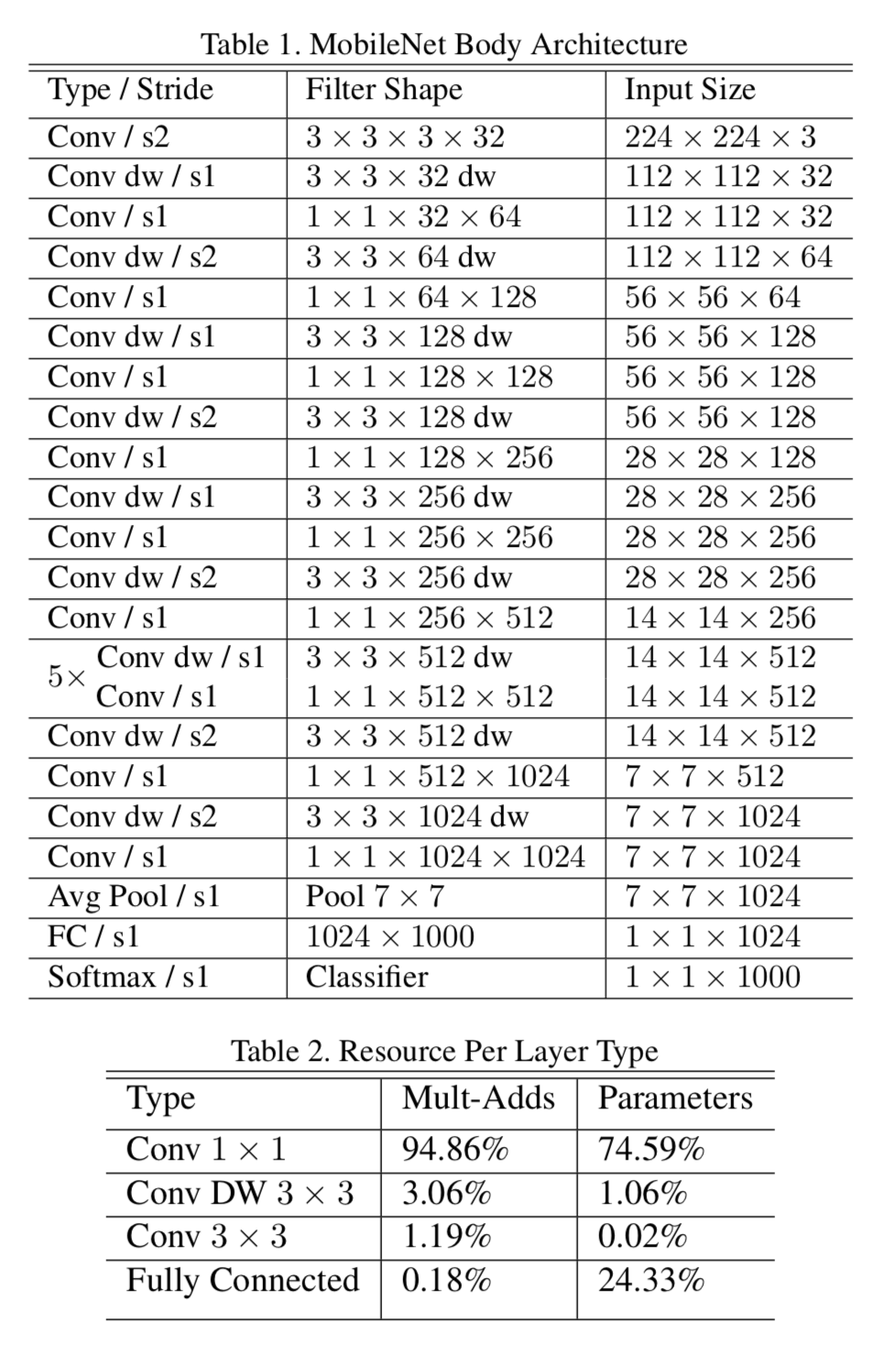
MobileNetの構造はTable1に示されている。全ての層がBatch NormalizationとReLUにしたがっており、最後の層は分類のためにSoftmaxが使われている。
Table2でわかるように、MobileNetはその計算のほとんどpointwise convolutionが占めている。
Figure3で、通常のCNN(左)とMobileNet(右)のNNの層の構成が示されている。

Width Multiplier: Thinner Models
上記で示したような、基本のMobileNetの構造でもすでに小さく、latencyも低いが、さらに小さく、速く動作するような構造が要求される場合もある。このような要求に応えるために、width multiplierと呼ばれるパラメータαを導入する。その結果、それぞれの層で、ネットワークを小さく揃えることが可能になる。
例えば、width multiplierであるαを導入すると、入力チャネル数MはαMに、出力チャンネル数NはαNになる。また、αはα ∈ (0, 1]の範囲を取り、一般的には、1, 0.75, 0.5, 0.25が用いられる。
Resolution Multiplier: Reduced Representation
次に、計算コストを削減するためのハイパーパラメータとしてresolution multiplierと呼ばれるパラメータρを導入する。これにより、各層の入力画像とその内部表現を削減することが可能になる。
例えば、resolution multiplierであるρを導入すると、入力画像の大きさDfはρDfに、出力画像の大きさDfはρDfになる。また、ρはρ ∈ (0, 1]の範囲を取る。
以下のTable3では、入力特徴マップサイズ14 × 14 × 512、カーネルサイズ3×3×512×512の時の、通常のCNNと、MobileNet、さらにハイパーパラメータαとρを導入した時の計算量とパラメータ数が比較されている。

Experiments
以下では、MobileNetの性能を様々に比較していく。
Model Choices
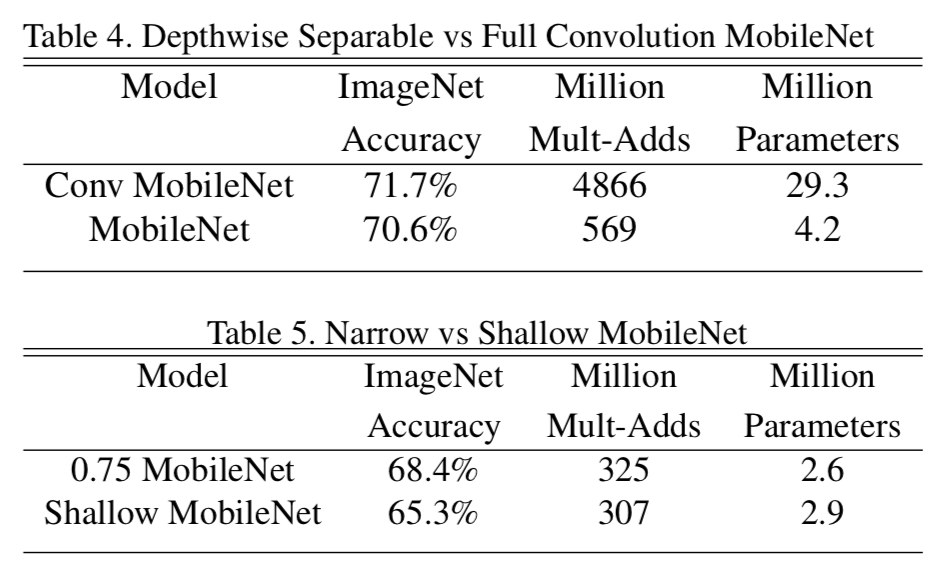
Table4では、全てConvolutionを使ったMobileNetとDepthwise Separable Convolutionを一部使ったMobileNetの性能を比較している。後者は、Multi-AddsもMiParametersも大きく減っているのに対して、Accuracyは1%ほどしか減っていないことがわかる。これにより、Depthwise Separable Convolutionを用いることで、通常の計算コストを大きく抑えながら同程度の精度が出せることがわかる。
またTable5では、width multiplierを導入した場合と、Table1のうちある1つの層を取り除いてShallow(浅くした)構造で比較をしている。どちらも計算コストを抑えるが、精度は3%ほど前者の方が高くなっている。
Model Shrinking Hyperparameters
Table6では、width multiplier αによる、精度と計算コストのトレードオフの関係が示されている。αを小さくすればするほど、計算コストは抑えられるが、その分精度は下がっている。
またTable7では、resolution multiplier ρによる精度と計算コストのトレードオフの関係が示されている。これもwidth multiplierと同様に、ρを小さくすればするほど、計算コストは抑えられるが、その分精度は下がっている。
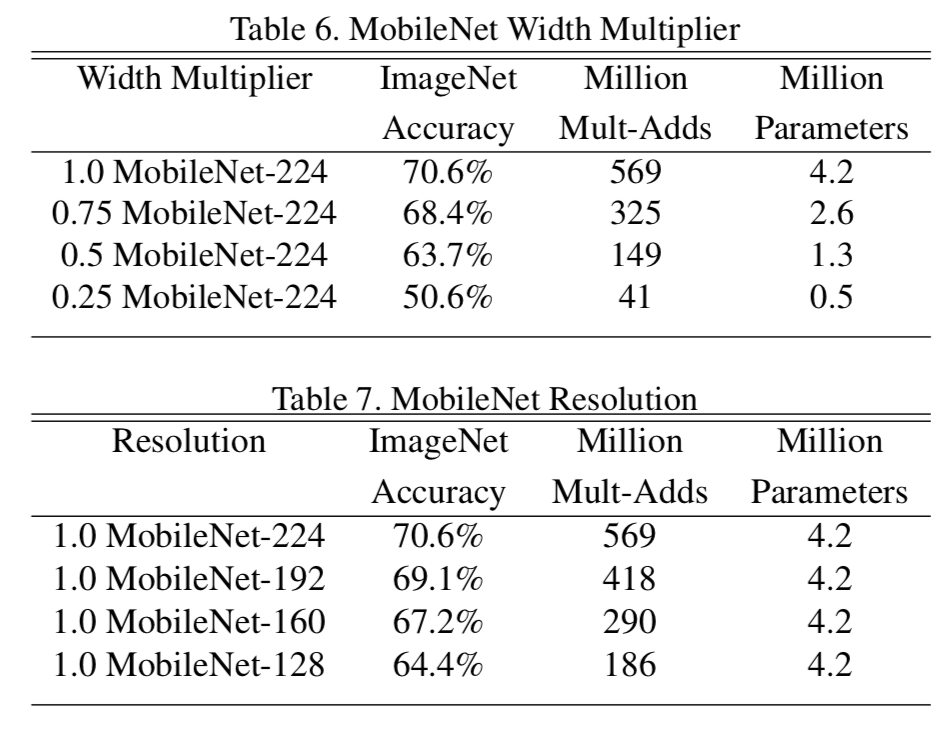
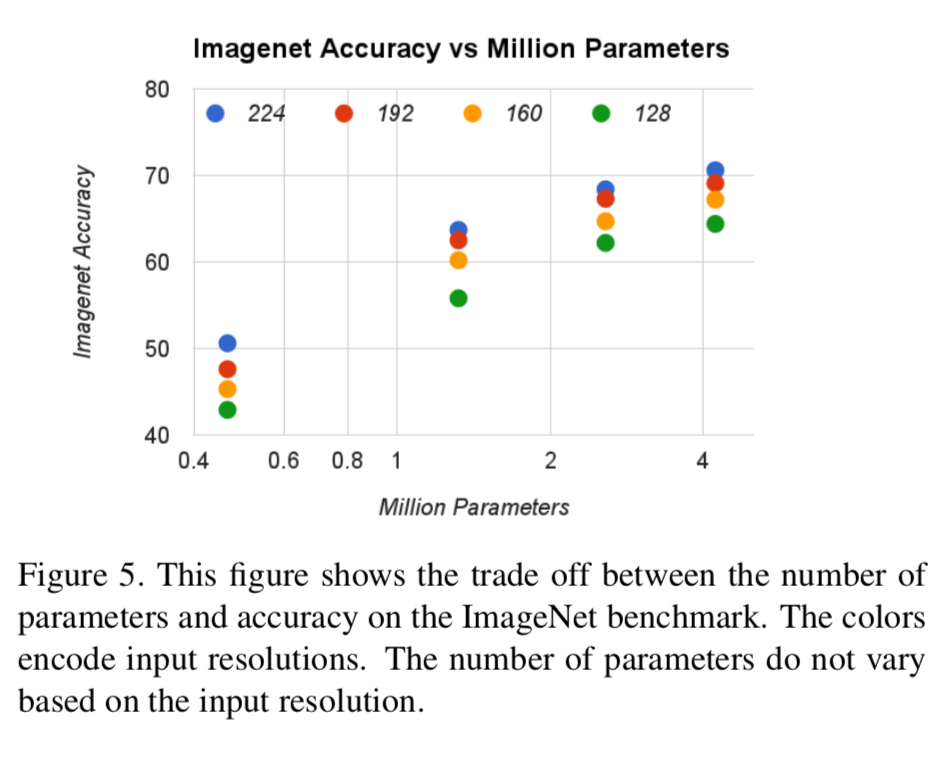
Figure5では、width multiplier α ∈ {1, 0.75, 0.5, 0.25}とresolutions {224, 192, 160, 128}とハイパーパラメータを設定した時の精度と計算コストの関係を示している。
Reference
データ分析を業務で1ヶ月間やってみて学んだ大原則
データ分析エンジニアになった
今までサーバーサイドエンジニア・インフラエンジニアとして仕事をしながら、簡単なデータ分析をして、施策に落としたり施策の効果を測定したりしていました。そして、ちょうど1ヶ月前からデータ分析エンジニアとして業務のほぼ100%をデータ分析関連の仕事に費やすことになりました。ここでは、データ分析に1ヶ月間のめり込んだことで見えた発見を記したいと思います。
ちなみに、自分がデータ分析としてやっていることは、
です。これらのKPIの可視化から、施策出し、施策の効果計測などを担当しています。
データ分析に対して感じていたこと
データ分析を実際に専任で始めるまでは、データ分析=SQL・統計・機械学習・python・数学など色々な単語が頭に浮かんでいました。高度な分析力を磨かないといけないと思っていました。
しかし、データ分析において基本中の基本はここではありませんでした。それは、
「仮説を立てること」「あえてスタンスを取ること」
の2つだという結論に行きつきました。もちろん上の統計などの力がとても効果を発揮する場面は多々ありますし、あって損は絶対にないスキルセットだと思います。しかし、プロダクトを伸ばすためのデータ分析にはもっと大切な大原則があることに気づきました。
仮説を立てて、あえてスタンスをとる
実際の業務上の例で考えてみます。「今月のメインページからの売り上げが落ちた」という問題があるとしましょう。アプリ内で課金に至る動線は色々ある中で、全体の80%を占めるページからのCV(コンバージョン)が下がっているというところまでわかっていたとします。この問題をデータ分析を用いて施策に落とし、解決するというのが分析のゴールです。
まずデータを探索するという誤り
さて、どうしますか?ここでいきなりデータを見るという誤りを起こしがちです。
- メインページに訪れるユーザーの属性を先月と比べてみよう
- ユーザーの滞在時間を先月と比べてみよう
- メインページのレスポンスタイムをみてみようか
このやり方はとても効率が悪いやり方です。データとその切り口は無限大であり、手当たり次第データを分析してみて正解を見つけるのはとても困難です。
仮説を立てる
手当たり次第データに手をつけないためにも、まずやることは「仮説を立てる」ことです。 メインページのCVが落ちたということは、メインページのUUが減ったか、CVRが落ちたかのどちらかです。このように、まずはロジカルに問題を分解してみます。
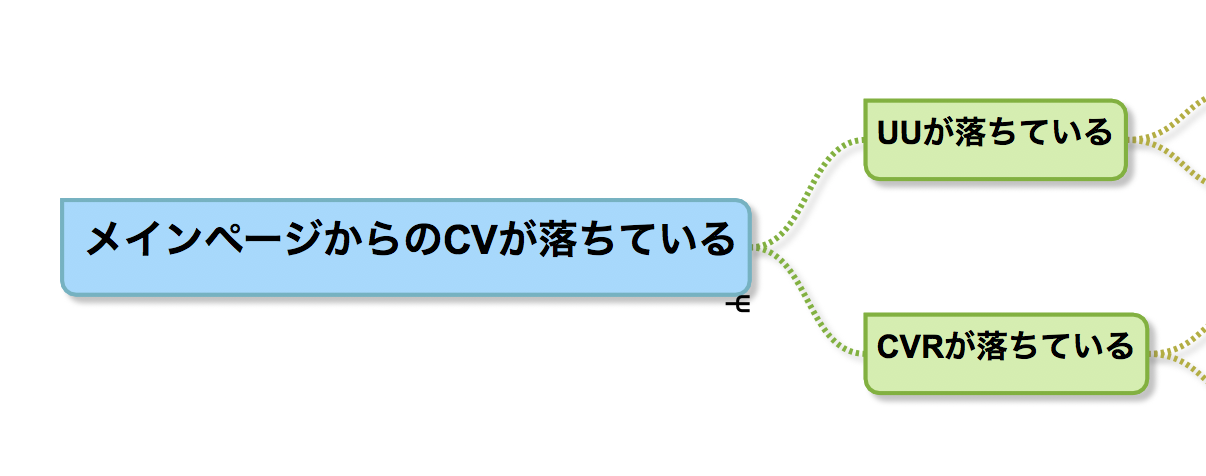
問題の分解に使える手法としてロジックツリーとMECEがあります。
ロジックツリー
「ロジックツリー」は、ある1つの課題や問題があるときに、どのような道筋でその事象を解決するのが適切なのか?を導き出すフレームワークです。 http://www.i-i-b.jp/blog/2903/logictree/
MECE
MECE(ミーシー、またはミッシー)は「Mutually Exclusive and Collectively Exhaustive」の略で、直訳すると「お互いに重複せず、全体に漏れがない」となります。 https://ferret-plus.com/4387
あえてスタンスを取る
CVが下がったという問題を、UUが下がったもしくはCVRが下がったという問題に分解しました。この原因となる仮説をさらに掘っていきたいところですが、ここでとても大切なことは、「あえてスタンスをとる」ということだと思っています。何を言いたいかというと、
- 絶対これが原因でこの問題が起こっているんだと断言できてしまうレベルまで仮説を具体的にする
- 分析をして根拠を出せばそのままレポートになってしまう
つまり、なんとなくで仮説をだすのではなく、一種の確信みたいなものが持てるくらい深いレベルの仮説に仕上げる必要があります。実際やって見るとかなりキツイのですが、あえてスタンスを取りに行かないと分析が曖昧になったり、分析が意味のないものになりがちです。

もはや、「きっとこの4つの原因のどれか数個が影響してメインページからのCVが落ちたんだろうな」というレベルまで落とし込んでしまいます。
分析する
あえてスタンスをとった仮説を出せたらあとはそれをデータを用いて検証していくだけです。あえてスタンスを取ったため分析が大変楽で簡潔なものになっていると思います。
- 検索ボリュームの大きいキーワードのSEO順位が下がったから
- 先月と今月で狙っているキーワードのSEOの順位を比較して見る
- 先月トップページからこのページへの導線を変えたから
- 先月と今月でトップページからこのページへの流入数・割合を比較して見る
- 先月CVボタンの色を変えたから
- 色を変えたボタン経由のCVRを比較して見る
- 先月サイドバーにあったCVポイントをヘッダーに移したから
- 先月と今月でページ内のCVポイントごとのCVRを比較して見る
あえてスタンスを取って「これが原因だ!!」と宣言してみたからこそ、見るべき指標は4つまで絞れています。そしてそれぞれの分析はとても簡単なものです。 もし、分析をした結果が満足のいくものではなかったら、その分析結果を示唆としてまた仮説を立て直してみてください。
アウトプットから考える
データ分析においては、ボトムアップにデータから何が導けるか...と考えがちですが、大切なのはトップダウンに進めること、これを「仮説を立ててあえてスタンスをとる」と表現しています。ゴールをシャープにすることで、見るべきデータをグッと絞り込むことが大切です。
イシューから始めよ
「イシューから始めよ」という本がこれらの考え方をとてもわかりやすく説明しています。

また、圧倒的に生産性の高い人(サイエンティスト)の研究スタイルという、この本のベースとなった記事もとてもわかりやすいです。
これらの考え方はデータ分析に限らず、とても汎用的かつ強力なものだと思います。
まとめ
この1ヶ月データ分析に取り組む中で、「仮説を立てろ」「スタンスをとれ」と言われ続けていました。すぐにデータに飛びついてしまいたくなる気持ちを抑えて、苦しいけれどあえてスタンスをとるような仮説を構築することで、分析がスムーズに進むことを感じました。
また3ヶ月、半年という節目で気づいたことをアウトプットしていきたいと思います。
window関数を使いこなす 〜分析のためのSQL〜
分析のためにSQLを使う際、window関数はとても便利です。一方でとっつきにくい考え方や、情報が少なかったりしてどうしても敬遠してしまいがちです。例を交えて簡単にまとめてみたいと思います。
window関数とは
PostgreSQLの公式ドキュメントには以下のように説明があります。
A window function performs a calculation across a set of table rows that are somehow related to the current row. This is comparable to the type of calculation that can be done with an aggregate function. But unlike regular aggregate functions, use of a window function does not cause rows to become grouped into a single output row — the rows retain their separate identities. Behind the scenes, the window function is able to access more than just the current row of the query result.
ポイントは
- 現在の行に関するテーブル全体を舐める計算をする
- 集約関数と考え方は似ている。集約関数は文字通り1行に集約するが、window関数を使った場合は対象の行はそのまま残る
- 対象の行全てに対して処理が行われる
と言ったところでしょうか。一方で、BigQuery StandardSQLのドキュメントには以下のように書かれています。
データベースでは、分析関数は行のグループ全体に対して集計値を計算する関数です。行のグループに対して単一の集計値を返す集計関数とは異なり、分析関数は入力行のグループに対して分析関数を計算することで、行ごとに単一の値を返します。
分析関数は複雑な分析オペレーションを簡潔に表す強力なメカニズムであり、分析関数を使用しなければコストの高いセルフ JOIN や SQL クエリ外での計算を行う必要が生じる評価を効率的に行えます。
分析関数は、SQL 標準や一部の商用データベースで「(分析)ウィンドウ関数」とも呼ばれています。これは、分析関数が window や window frame と呼ばれる行のグループに対して評価されるためです。その他の一部のデータベースでは、オンライン分析処理(OLAP)関数と呼ばれることもあります。
文字だけではわかりにくいので実際の例で確認していきます。
部署ごとの平均賃金が欲しい
depname | empid | salary -----------+-------+-------- develop | 11 | 5200 develop | 7 | 4200 develop | 9 | 4500 develop | 8 | 6000 develop | 10 | 5200 personnel | 5 | 3500 personnel | 2 | 3900 sales | 3 | 4800 sales | 1 | 5000 sales | 4 | 4800
部署・従業員ID・賃金を持つテーブルを使って考えます。このテーブルの名前はemp_infoテーブルとします。 例えば、行ごとに部署ごとの平均賃金を追加したいと考えます。アウトプットイメージは以下の通りです。
depname | empid | salary | avg_salary -----------+-------+--------+------------- develop | 11 | 5200 | 5020 develop | 7 | 4200 | 5020 develop | 9 | 4500 | 5020 develop | 8 | 6000 | 5020 develop | 10 | 5200 | 5020 personnel | 5 | 3500 | 3700 personnel | 2 | 3900 | 3700 sales | 3 | 4800 | 4866 sales | 1 | 5000 | 4866 sales | 4 | 4800 | 4866
普通に集約関数(GROUP BY)を使ってみます。
SELECT depname, AVG(depname) AS avg_salary FROM emp_info GROUP BY depname
得られる結果は、
depname | avg_salary -----------+-------- develop | 5200 personnel | 3700 sales | 4866
です。(簡略化のため小数点以下はカットしています)(このテーブルの名前はdep_avg_salaryとします) 完全に集約されてしまいました。各行に平均賃金を追加したいのですが部署ごとの平均賃金が出てしまいました。
SELECT emp_info.depname, emp_info.empid, emp_info.salary, dep_avg_salary.avg_salary FROM emp_info INNER JOIN dep_avg_salary ON emp_info.depname = dep_avg_salary.depname
とやれば欲しい答えが出ますが、計算量が多いですね。もっと簡単にやります。 ここでwindow関数が登場します。
SELECT depname, empid, salary, AVG(salary) OVER (PARTITION BY depname) FROM emp_info;
これが求めたい結果です。
depname | empid | salary | avg_salary -----------+-------+--------+------------- develop | 11 | 5200 | 5020 develop | 7 | 4200 | 5020 develop | 9 | 4500 | 5020 develop | 8 | 6000 | 5020 develop | 10 | 5200 | 5020 personnel | 5 | 3500 | 3700 personnel | 2 | 3900 | 3700 sales | 3 | 4800 | 4866 sales | 1 | 5000 | 4866 sales | 4 | 4800 | 4866
OVERとPARTITION BYという2つの関数が出てきました。続いてこれらを解説します。
OVERはwindow関数を使いますよーというサインです。OVERの後に、どのようにwindowを作るのかということを定義します。 PARTITIONでwindow、つまりどの範囲でグループを作るか指定します。
AVG(salary) OVER (PARTITION BY depname)は、depnameでグループを作った上で、自分が属するdepnameのsalaryのAVGをちょうだいと言っています。
部署ごとの給料ランキングが欲しい
以下のような結果が欲しいとします。
depname | empid | salary | rank_salary -----------+-------+--------+------------- develop | 11 | 5200 | 2 develop | 7 | 4200 | 4 develop | 9 | 4500 | 3 develop | 8 | 6000 | 1 develop | 10 | 5200 | 2 personnel | 5 | 3500 | 2 personnel | 2 | 3900 | 1 sales | 3 | 4800 | 2 sales | 1 | 5000 | 1 sales | 4 | 4800 | 2
これもwindow関数を使っていきましょう。
SELECT depname, empid, salary, RANK() OVER (PARTITION BY depname ORDER BY salary DESC) AS rank_salary FROM emp_info;
これも前から読んでいきます。RANK()が欲しいと言っています。次にどの範囲のランキングが欲しいのか指定します。 OVERでwindow関数を使うことを指定します。depnameごとにwindowを作ってその中でsalaryの大きい順で並べます。 こうすると、部署ごとで自分の賃金がいくらかゲットできます。
指定した順番通りに番号を割り振りたい
次は、先ほどのデータに入社日を加えたテーブルで考えてみます。
depname | empid | salary | enter_date -----------+-------+--------+------------- develop | 11 | 5200 | 2018-01-15 develop | 7 | 4200 | 2018-04-15 develop | 9 | 4500 | 2018-02-01 develop | 8 | 6000 | 2018-01-01 develop | 10 | 5200 | 2018-04-01 personnel | 5 | 3500 | 2018-03-01 personnel | 2 | 3900 | 2018-02-15 sales | 3 | 4800 | 2018-01-31 sales | 1 | 5000 | 2018-02-15 sales | 4 | 4800 | 2018-04-01
部署ごとに入社日順に番号を割り振りたいとなったとします。 ROW_NUMBER()関数を使います。
SELECT depname, empid, salary, ROW_NUMBER() OVER (PARTITION BY depname ORDER BY enter_date) AS enterid FROM emp_info;
depnameごとにwindowを作ってenter_date順に並べます。それにROW_NUMBERを付与するのです。 すると以下のようにアウトプットされます。
depname | empid | salary | enter_date| enterid -----------+-------+--------+------------+-------- develop | 11 | 5200 | 2018-01-15| 2 develop | 7 | 4200 | 2018-04-15| 5 develop | 9 | 4500 | 2018-02-01| 3 develop | 8 | 6000 | 2018-01-01| 1 develop | 10 | 5200 | 2018-04-01| 4 personnel | 5 | 3500 | 2018-03-01| 2 personnel | 2 | 3900 | 2018-02-15| 1 sales | 3 | 4800 | 2018-01-31| 1 sales | 1 | 5000 | 2018-02-15| 2 sales | 4 | 4800 | 2018-04-01| 3
1つ前・1つ後に入社した従業員の入社日を知りたい
LAG/LEAD関数を使います。LAGは前、LEADは後です。 2つ引数をとります。第一引数は指定カラム、第二引数は何個前・後を指定するかです。
SELECT depname, empid, salary, enter_date, LAG(enter_date) OVER (ORDER BY enter_date) AS prev_enter_date, LEAD(enter_date) OVER (ORDER BY enter_date) AS post_enter_date, FROM emp_info;
depname | empid | salary | enter_date| prev_enter_date| post_enter_date -----------+-------+--------+------------+----------------+------------------ develop | 11 | 5200 | 2018-01-15| 2018-01-01| 2018-01-31 develop | 7 | 4200 | 2018-04-15| 2018-04-01| NULL develop | 9 | 4500 | 2018-02-01| 2018-01-31| 2018-02-15 develop | 8 | 6000 | 2018-01-01| NULL| 2018-01-15 develop | 10 | 5200 | 2018-04-01| 2018-03-01| 2018-04-15 personnel | 5 | 3500 | 2018-03-01| 2018-02-15| 2018-04-01 personnel | 2 | 3900 | 2018-02-15| 2018-02-01| 2018-03-01 sales | 3 | 4800 | 2018-01-31| 2018-01-15| 2018-02-01 sales | 1 | 5000 | 2018-02-15| 2018-02-01| 2018-03-01 sales | 4 | 4800 | 2018-04-01| 2018-03-01| 2018-04-15
この場合、例えば「同じ部署で1つ前に入社した従業員の入社日」が欲しいのならば、LAG(enter_date) OVER (PARTITION BY depname ORDER BY enter_date)としますが、今回はwindowの指定がない、つまり全体に対してなのでPARTITION BYは不要です。1つ前、1つ後を求めるのは一見とても面倒に見えますが、LAG/LEADとwindow関数を用いれば簡単にできます。
また、LAG/LEAD関数は引数を3つとります。LAG(column [,offset] [,default])です。columnは必須で、1つ前のどのカラムを返すのかを指定します。offsetはデフォルトでは1です。現在の行より何個前の値を返すか指定できます。defaultは1つ前が存在しないときに何を返すかです。デフォルトはNULLです。
参考情報
BigQuery StandardSQL 分析関数
分析関数が図と共にとても丁寧に解説されています。
PostgreSQL window functions
こちらも丁寧に解説しています。
SQL window functions
説明はちょっと雑ですが、どんな関数があるかを見渡すのに役立ちます。
pythonでデータを可視化したいならseabornを使おう!
pythonでデータを可視化するのにmatplotlibを使う人は多いと思いますが、seaboarnというmatplotlibのラッパーが素晴らしく便利です。
インストール
まずはseabornをインストールします。pipもしくはcondaでインストールできます。
pip install seaborn
conda install seaborn
前準備
seabornはnumpy, matplotlib, pandasに依存しているので、同時にimportします。
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import pandas as pd import seaborn as sns %matplotlib inline
サンプルデータとして、titanic,tips,irisのデータセットを使います。
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
iris = sns.load_dataset("iris")
変数分布を知る
とりあえずある変数の分布はどうなっているのだろう?と可視化することはよくあります。seaboarnだと、matplotlib以上の情報を簡単に与えてくれるため、得られるインサイトの費用対効果がとても大きいです。早速見てみましょう。
1変数の場合(distplot)
まず、データを用意します。標準正規分布に従う乱数を100件用意しておきます。
x = np.random.normal(size=100)
distplot()関数を使うと、ヒストグラムとKDEが同時に表示されます。これだけでも結構便利です。ヒストグラムだけ表示したり、より細かい分布をみたり等の調節もできます。
sns.distplot(x)

2変数の場合(jointplot)
次に、変数をxとyの2つに増やしてみます。pandasのDataFrameを用います。
mean, cov = [0, 1], [(1, .5), (.5, 1)] data = np.random.multivariate_normal(mean, cov, 200) df = pd.DataFrame(data, columns=["x", "y"]) df.head()
こんなデータです。
x y 0 1.512856 2.527512 1 0.311464 2.143966 2 0.774056 1.870894 3 -0.995346 -0.371048 4 0.756758 2.866903
2変数の分布を可視化するのには、jointplot()関数を用います。x軸・y軸・dataを指定してあげればOKです。2変数の散布図・各変数のヒストグラムが同時に見られます。素晴らしすぎる。
sns.jointplot(x="x", y="y", data=df)

カテゴリ情報を知る
データを眺めるとき、「カテゴリごとに変数の分布がどうなっているか」などカテゴリごとに変数の特徴を押さえたいケースがよくあります。seabornはカテゴリに対する可視化にもうってつけです。
カテゴリごとのデータの分布を見る
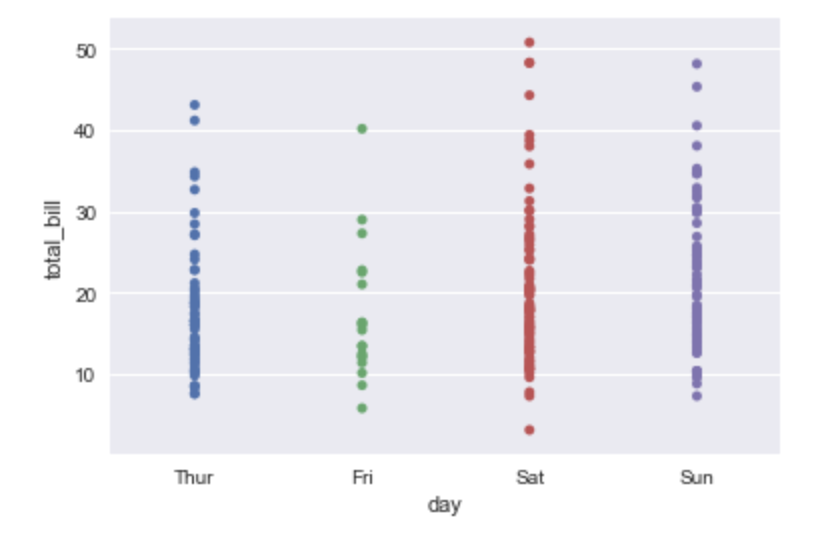
曜日ごとにチップとして支払われている額に傾向があるのか、男性・女性では、喫煙かどうかは影響するの? はい、stripplot()関数を使えば一発で可視化できます。
sns.stripplot(x="day", y="total_bill", data=tips)
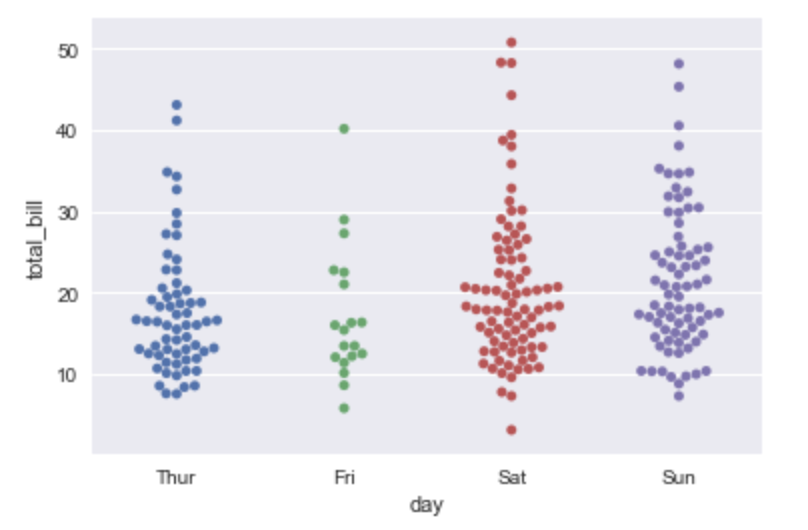
swarmplot()関数にすると、データの分布が重ならないように調節してくれます。
sns.swarmplot(x="day", y="total_bill", data=tips)
hueという引数に新たな変数を設定することで、新たな変数を加えることができます。性別という情報も加えて可視化してみます。どこまでやってくれるんだseabornは。
sns.swarmplot(x="day", y="total_bill", hue="sex", data=tips)

カテゴリごとのデータの分散を見る
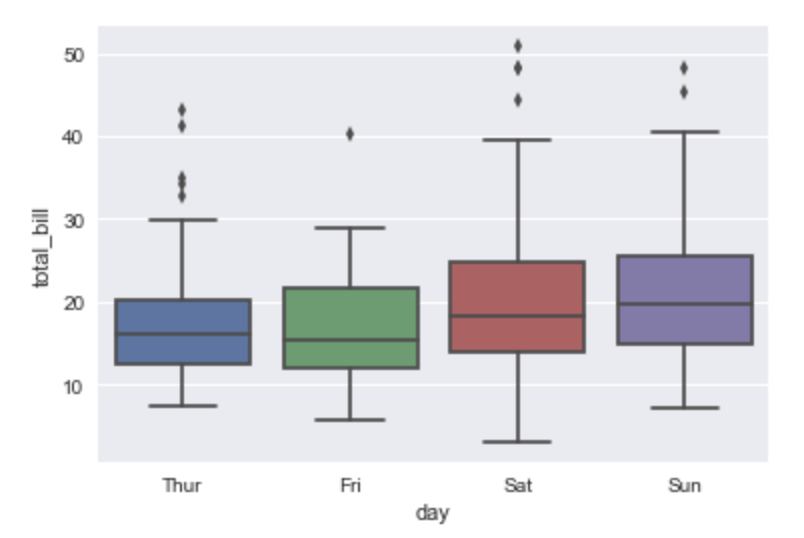
箱ひげ図を用いてデータを可視化することで、上の散布図で見るよりも正確にデータを捉えることができます。boxplot()関数を用います。
sns.boxplot(x="day", y="total_bill", data=tips)
統計的にデータを推定する
barplot()関数を用いて、棒グラフを書くことができます。以下ではtitanicのデータセットを使います。性別・客室の階級と生存有無にどのような関係があるかを一発で可視化しています。
sns.barplot(x="sex", y="survived", hue="class", data=titanic)
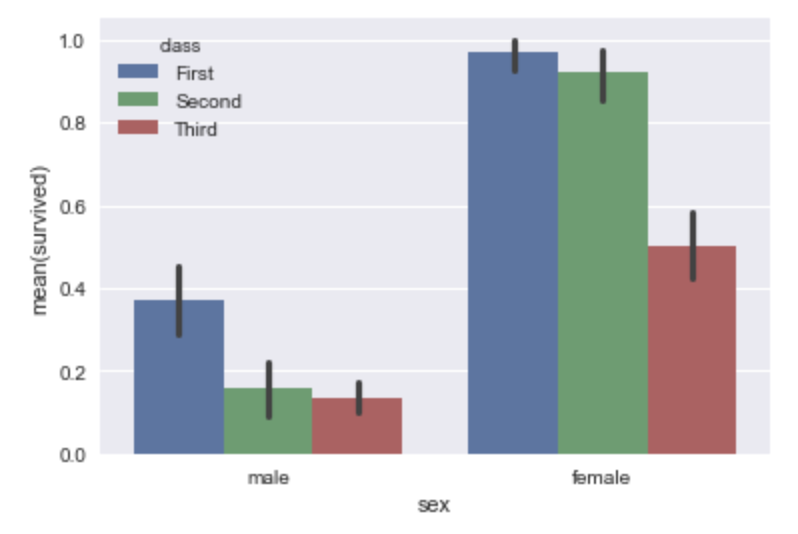
poitplot()関数を用いることで、上のデータをシンプルに置き換えることができます。
sns.pointplot(x="sex", y="survived", hue="class", data=titanic)

線形回帰モデルを知る
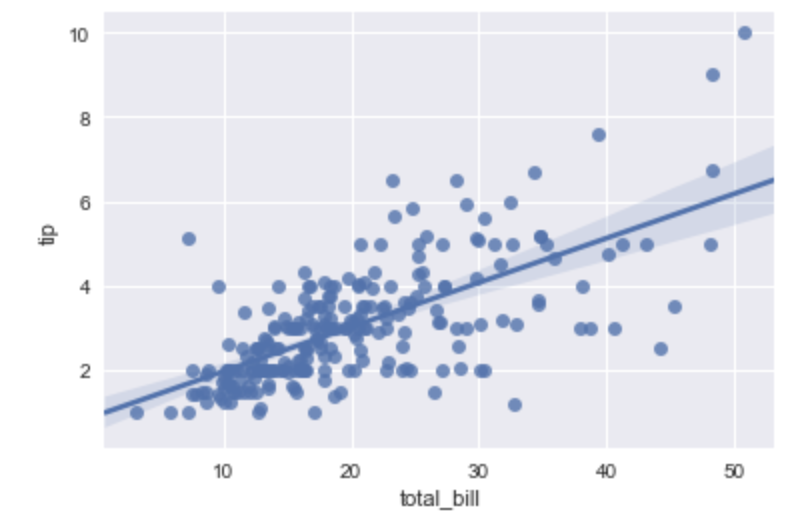
線形回帰直線を描く
seabornを使えば、分布図の上に線形回帰直線を引くのも一瞬でできます。regplot()関数を用います。
sns.regplot(x="total_bill", y="tip", data=tips)
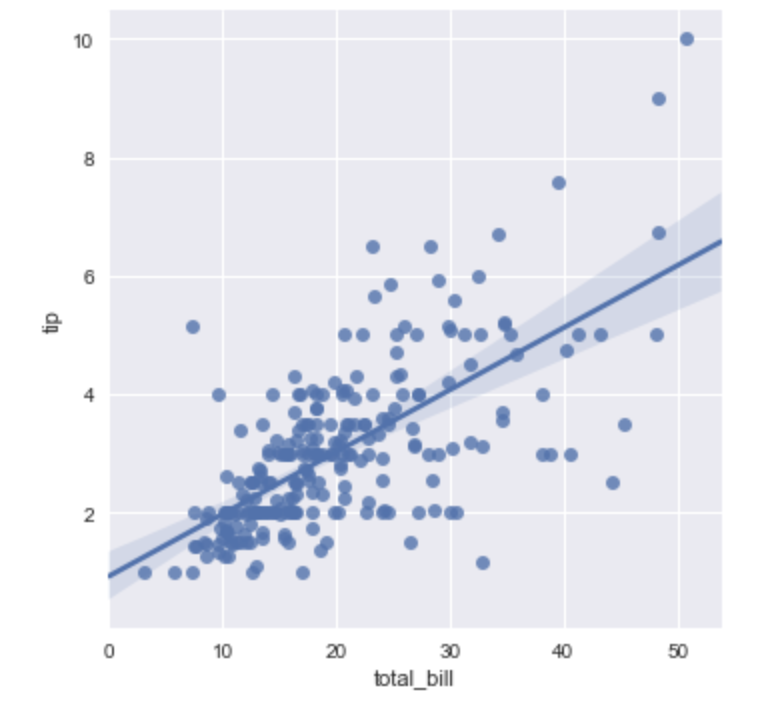
同じことは、lmplot()関数でもできます。両者の違いは、regplot()は、データをpandas.Seriesやpandas.DataFrameなどどのような形で渡しても良い一方で、lmplot()は、必ずxとyを指定しなければならない点です。
sns.lmplot(x="total_bill", y="tip", data=tips)
上と同じように、hueを与えれば変数を増やして可視化することができます。
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)

巨大なデータセットから効率よくインサイトを得る
とりあえずデータが手元にあるけど、何もわかっていない。どこから手をつけたらいいのやら、、、となった場面でもseabornが活躍します。irisのデータセットを用います。pairplot()関数を用いることで一気に関係性を可視化できます。これは、データを触りはじめる一番最初にやりたいことです。
sns.pairplot(iris, hue="species", size=2.5)

まとめ
seabornを使ってデータを可視化してみました。今までmatplotlibを使ってデータを可視化していた自分としては、素晴らしいの一言につきます。データを触っている以上、それを可視化してインサイトを得ることは基本中の基本なので、これだけ便利にかつ高性能に可視化をしてくれるツールは使わなければなりません。